
みなさん,こんにちは。
シンノユウキ(shinno1993)です。
以前の記事でVGG16を用いて画像を認識・分類する方法を紹介しました。

しかし栄養士である私としては,やはり食事画像認識をやりたいなーと思っていまいた。
ということで,VGG16をFine-tuningし,食事画像を認識できるようなプログラムを書いてみたいと思います。データ・セットにはUECFOOD-100を使用します。
開発環境を整えよう
「Google Colaboratory」を使おう
まずは開発環境を用意しましょう。一応,Google Colaboratoryを利用されることを想定して話を進めていきます。予め機械学習に必要なライブラリもインストールされていますし,機械学習に必要なGPUも利用できるからです。まだ用意されていないという方は,以下の記事を参考に用意してみてください。

必要なライブラリなどをインポートしよう
次に,必要なライブラリなどをインポートしましょう。以下のコードを実行してください:
import keras
from keras.applications import VGG16
from keras.models import Sequential, load_model
from keras import models, optimizers
from keras.optimizers import SGD
from keras.layers import Input, Dense, Dropout, Activation, Flatten
from keras.preprocessing.image import list_pictures, load_img, ImageDataGenerator
from keras.callbacks import CSVLogger, ModelCheckpoint
import shutil
import numpy as np
from PIL import Image
!mkdir ./UECFOOD100/dataset
!mkdir ./UECFOOD100/dataset/{1..100}
uecfood_dir = './UECFOOD100/'
dataset_dir = uecfood_dir + 'dataset/'- 1-11行目:必要なライブラリだったりパッケージだったりをインポートしています。後ほどこれらを使用していきますので,とりあえず意味を理解せずに実行してください。
- 13行目:データを入れるためのディレクトリを作成しています。
mkdirディレクトリ名 でディレクトリを作成できますので,!mkdir ./UECFOOD100/datasetで作成しちゃいましょう。 - 14行目:13行目で作成したディレクトリに,1~100までのディレクトリを作成しています。
{1..100}とすることで1から100までの連続的な表現として扱ってくれますので,こうかくことで連番のディレクトリを作成できます。 - 15,16行目:変数にディレクトリのパスを代入しています。このようにすることで後々のファイル操作などが楽になるのでぜひやっておきましょう。
学習用画像のデータセットを用意しよう
まずはデータをダウンロードしよう
VGG16をFine-tuningし,食事画像をしっかりと認識できるようにするためには大量の正解ラベルがついた食事画像が必要です。しかし個人でそれを準備するのはかなり大変。
ということで,今回は電気通信大学の柳井啓司教授の研究室で作成された「UECFOOD-100」を利用していきます。詳細は以下のURLからご確認ください。

データのダウンロードには以下のコードを実行してください:
!wget http://foodcam.mobi/dataset100.zip
!unzip dataset100.zip
!ls UECFOOD100エクスクラメーションマーク(!)を行頭につけるとLinuxコマンドを使うことができます。
wgetは指定したURLからファイルをダウンロードできるコマンドです。ダウンロードされたファイルはzipファイル形式で保存されていますので,それをunzipコマンドで解凍しましょう。
そうすると,「UECFOOD100」というフォルダが生成されます。ためしに,その中身を表示してみましょう。lsコマンドでディレクトリを指定するとその中身を確かめることができます。以下のような結果が表示されるはずです:
1 17 25 33 41 5 58 66 74 82 90 99
10 18 26 34 42 50 59 67 75 83 91 category_ja_euc.txt
100 19 27 35 43 51 6 68 76 84 92 category_ja_sjis.txt
11 2 28 36 44 52 60 69 77 85 93 category_ja_utf8.txt
12 20 29 37 45 53 61 7 78 86 94 category.txt
13 21 3 38 46 54 62 70 79 87 95 multiple_food.txt
14 22 30 39 47 55 63 71 8 88 96 README.txt
15 23 31 4 48 56 64 72 80 89 97
16 24 32 40 49 57 65 73 81 9 98このうち,1-100までのフォルダにそれぞれ食事画像が入力されています。このそれぞれのフォルダのフォルダ名が正解用ラベルとなっています。たとえば,フォルダ:1に含まれるのは白ごはんの画像です。どの数字がどのラベルに該当するかは,このDirectoryに保存されている「category_ja_utf8.txt」などに格納されていますので確認してみるとよいでしょう。
BBに従って画像をトリミングしよう
次に,ダウンロードした画像データを適切な形に加工していきましょう。実は,ダウンロードしたままの画像の状態では,複数の食事画像が含まれていたり,画像の端の方に該当の食事が写っていたりして,学習用のデータとしては適切ではありません。
さっそく,画像データを適切な形にトリミングしていきましょう。UECFOOD100にはトリミングすべき範囲をしめすBB(Bounding Box)情報がテキストファイルが含まれていますので,それに従ってトリミングしていきます。以下のコードを実行してください:
for ctg_index in range(1,100):
bb_info = []
for line in open(uecfood_dir + str(ctg_index) + '/bb_info.txt', 'r'):
bb_info.append(line[:-1].split())
# 1行目はラベル行なので削除
bb_info.pop(0)
for line in bb_info:
filename = line[0] + '.jpg'
pic_img = Image.open(uecfood_dir + str(ctg_index) + '/' + filename)
x1 = int(line[1])
y1 = int(line[2])
x2 = int(line[3])
y2 = int(line[4])
area = (x1, y1, x2, y2)
pic_crop = pic_img.crop(area)
# 新しく別のファイルとして保存
pic_crop.save(dataset_dir + str(ctg_index) + '/' + filename, quality=100)- 1行目:食事画像とそのBB情報(バウンディングボックスの情報 トリミングする範囲)は,それぞれのディレクトリごとに格納されていますので,ディレクトリごとに処理を行っていきます。その繰り返し処理を行っているのが
for ctg_index in range(1,100):の部分です。 - 2-6行目:BB情報の格納されたテキストファイルから情報を抜き出しています。取り出した情報の1行目はラベル行で不要ですので
bb_info.pop(0)で削除しています。 - 8-16行目:
bb_infoに従って画像ごとにトリミングしています。image.open(ファイルパス)で画像を取得できますのでまずは画像を取得しておきます。次に,bb_infoからトリミングする座標を取得します。行の1-4つめにx1, y1, x2, y2の座標が含まれますので,それを取得し,範囲として格納しています。トリミングするためにはcropメソッドを使って次のように記述できます。image_crop = image.crop((x1, y1, x2, y2))とすることで,指定の座標でトリミングされた画像を取得できます。 - 18行目:トリミングした画像をディレクトリ:datasetにカテゴリごとに保存しなおしています。
画像をトレーニング用とテスト用に分類しよう
次に,画像をトレーニング用とテスト用に分類していきましょう。
Kerasで機械学習する場合,トレーニング用のディレクトリと,テスト用のディレクトリに分けると便利です。ちょうど,以下のような形になると考えればわかりやすいでしょうか。
├─test
│ ├─1
│ ├─2
│ └─3
└─train
├─1
├─2
└─3ですので,まずは以下のコードを実行して,上記のようなディレクトリを作成してください:
!mkdir ./UECFOOD100/dataset/train
!mkdir ./UECFOOD100/dataset/test
!mkdir ./UECFOOD100/dataset/train/{1..100}
!mkdir ./UECFOOD100/dataset/test/{1..100}では,画像データを実際に分けていきましょう。コードは以下のようになります:
train_dir = dataset_dir + 'train/'
test_dir = dataset_dir + 'test/'
for ctg_index in range(1,100):
for pic in list_pictures(dataset_dir + str(ctg_index)):
if np.random.rand(1) < 0.2:
shutil.move(pic, test_dir + str(ctg_index))
else:
shutil.move(pic, train_dir + str(ctg_index))- 1,2行目:トレーニング用とテスト用のディレクトリのパスを変数に代入しています。
- 4行目:カテゴリごとに処理を繰り返しています。
- 5行目:ディレクトリの画像ごとに処理を繰り返しています。
list_pictures(ディレクトリのパス)でディレクトリの画像を全て取得できますので,その画像をpicに代入しながら繰り返しています。 - 6-9行目:画像をランダムにトレーニング用とテスト用に分類しています。
np.random.rand(1)で0.0以上1.0未満の乱数を生成しています。それが0.2未満の場合はテスト用の,それ以上の場合はトレーニング用のディレクトリにそれぞれ移動させています。移動にはshutil.move(移動する画像, 移動先のディレクトリ)を使っています。
これで画像をランダムに振り分けることができました!
モデルを構築しよう
ではモデルを構築していきましょう。今回はVGG16という学習済みのモデルをFine-tuningし,効率的に精度の良いモデルを作成していきます。早速ですが,以下のコードを入力してください:
image_size = 224
vgg_conv = VGG16(weights='imagenet', include_top=False, input_shape=(image_size, image_size, 3))
for layer in vgg_conv.layers[:-4]:
layer.trainable = False
model = models.Sequential()
model.add(vgg_conv)
model.add(Flatten())
model.add(Dense(1024, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(100, activation='softmax'))
model.summary()コードの解説をする前に,VGG16のモデル構造について説明します。VGG16では13の畳み込み層と3つの全結合層から成ります。これらの層のうち,最初の浅い部分では全般的な特徴を学習し,深い部分ではその画像特有の特徴を学習すると言われています。この浅い部分を再利用し,深い部分を調整するのがfine-tuningです。そのため,Fine-tuningをすることで,従来よりも少ない画像かつ少ない時間で効率的にモデルを構築することができるようになるのです。
では,コードを解説していきます。
- 3行目:VGG16のモデルをダウンロードしています。
- weights:重みの初期値を表しています。None でランダムな初期値を,'imagenet' でImageNetで学習した重みを設定します。今回は
weights='imagenet'を設定してください。 - include_top:モデルに全結合層を含むかどうかを指定します。
Trueだと全結合層を含み,Falseだと含みません。今回は全結合層を捨てて新しく作り直しますので,Falseを指定してください。従来のVGG16の全結合層は,ImageNetの1000のクラスに分類するように作成されており,今回の食事に特化した100のクラスに分類するようにはできていません。なので,その部分は利用せずに新たに作成します。 - input_shape:入力する画像の大きさや形状を示しています。今回は224×224のRGB配列の画像を入力しますので,
input_shape=(image_size, image_size, 3)で問題ありません。
- weights:重みの初期値を表しています。None でランダムな初期値を,'imagenet' でImageNetで学習した重みを設定します。今回は
- 4,5行目:レイヤーのパラメータを最後の4層を除き固定しています。先でも説明しましたが,今回はVGG16の浅い部分は効率的に再利用します。しかしデフォルトでは,その部分まで再度学習されてしまい,Fine-tuningのメリットを活かすことができません。なので
layer.trainable = falseとすることで学習されることを防いでいます。 - 7行目:モデルのインスタンスを生成しています。
- 8行目:空のモデルに先ほど作成した
vgg_convを追加しています。 - 10-13行目:モデルに全結合層を新しく追加しています。13行目は出力層で,最終的に100クラスに分類することから100の出力空間を指定しています。また,それらの層にどの程度合致するのか,確率的な表現を行うために活性化関数に
softmaxを用いています。
最後にモデルの構造を出力しています。以下のようになります:
Layer (type) Output Shape Param #
=================================================================
vgg16 (Model) (None, 7, 7, 512) 14714688
_________________________________________________________________
flatten_1 (Flatten) (None, 25088) 0
_________________________________________________________________
dense_1 (Dense) (None, 1024) 25691136
_________________________________________________________________
dropout_1 (Dropout) (None, 1024) 0
_________________________________________________________________
dense_2 (Dense) (None, 100) 102500モデルに画像を学習させていこう
まずは学習の準備から
では作成したモデルに,用意した画像を学習させていきましょう。まずは以下のコードを実行して学習するための準備を整えていきましょう:
batch_size = 32
train_datagen = ImageDataGenerator(
rescale = 1.0 / 255,
rotation_range=20,
width_shift_range=0.2,
height_shift_range=0.2,
horizontal_flip = True
)
validation_datagen=ImageDataGenerator(rescale=1.0/255)
train_generator=train_datagen.flow_from_directory(
train_dir,
target_size=(image_size,image_size),
batch_size=batch_size,
class_mode='categorical',
shuffle=True
)
validation_generator=validation_datagen.flow_from_directory(
test_dir,
target_size=(image_size,image_size),
batch_size=batch_size,
class_mode='categorical',
shuffle=True
)
model.compile(loss='categorical_crossentropy',
optimizer=optimizers.SGD(lr=1e-4, momentum=0.9),
metrics=['accuracy'])- 3-9行目:ImageDataGeneratorを使って画像を水増しし,学習に適切な形に変形しています。
- rescale:データを整形するために使っています。1.0 / 255 と指定することで画像のピクセル値を0.0~1.0の範囲に正規化しちえます。
- rotation_range:画像を水増しするために画像を回転させます。その回転の範囲を範囲を指定しています。
- width_shift_range:画像を水増しするために画像を水平方向にシフトさせる範囲を指定しています。
- height_shift_range:画像を水増しするために画像を垂直方向にシフトする範囲を指定しています。
- horizontal_flip:画像を水平方向に回転させるかどうかを指定します。True で回転させ,False だとさせません。
- 11行目:テスト用のデータを整形しています。テスト用データを水増しする必要はないのでrescale=1.0/255 のみを引数に指定しています。
- 13-19行目:学習させるための画像を,ディレクトリから取得するためのバッチを取得しています。
- directory:最初の引数にはトレーニング用の画像が含まれたディレクトリのファイルパスを指定します。
- target_size:画像のサイズを指定します。ピクセル値で指定してください。今回は224 を指定しています。
- batch_size:一度に取り出して学習させる画像の数を指定しています。今回は32 ですね。
- class_mode:どのような型でもって正解用のラベルを返すのかを指定します。'categorical' とすることでディレクトリ名を正解用のラベル(型は2次元のone-hotベクトル)とすることができます。
- shuffle:画像をシャッフルするかどうかを指定できます。今回はTrue を指定しています。
- 21-27行目:テスト用データもトレーニング用データと同様の処理を行っています。
- 29-31行目:モデルをコンパイルしています。
- loss:損失関数を指定します。今回は交差エントロピー誤差を利用しています。損失関数はディープ・ラーニング時にパラメータ修正の指標となるものです。損失を小さくなる方向にパラメータを修正する際に,この損失関数を用います。一般的に多分類を行う場合は交差エントロピー誤差が利用されるようなので,それを利用しています。
- optimizer:SGDを指定しています。SDGはStochastic Gradient Descent : 確率的勾配降下法と呼ばれる,基本的なアルゴリズムです。lrはLearning Rata:学習率のことで1回の学習でどれだけ学習するのかを,パラメータを更新するのかを指定しています。momentumには一般的に0.9という値が設定され,これを設定することでより早くパラメータを最適にすることができます。
- metrics:一般的に'acuracy' が用いられますのでそちらを指定しています。
学習させよう
では実際に学習させていきましょう。なお,今回の学習はGPU環境でもかなりの長い時間が必要なります。Google Colabを利用する場合はランタイムの切断やリセットなどにお気をつけください。以下のコードを実行しましょう:
csv_logger = CSVLogger('food_recongition.log')
hist=model.fit_generator(
train_generator,
epochs=100,
verbose=1,
validation_data=validation_generator,
callbacks=[csv_logger]
)
#save weights
model.save('food_recognition.h5')- 1行目:学習のログをCSVに保存していあます。
- 2-8行目:モデルに画像を学習させています。
- generator:最初の引数にはトレーニング用データのgeneratorを指定します。今回の場合はtrain_generator ですね。
- epochs:モデルを訓練させる回数です。多ければ良いというわけではありませんが,少ない場合は十分な精度が得られない場合があります。今回は100 を指定しています。
- verbose:訓練の進行状況の表示モードです。1を指定することで訓練ごとにプログレスバーが表示されます。
- validation_data:テスト用データを指定します。
- callbacks:訓練の際に呼ばれるコールバックを指定します。今回は訓練の結果をCSV形式でログを残すcsv_logger を指定しています。
- 10,11行目:モデルを保存しています。必要に応じて,こちらのモデルをローカルなどに保存しておきましょう。
これでモデルに学習させることができました!
では,学習の結果を見てみましょう。CSV形式でログを残しましたので,その結果をグラフにしてみました。
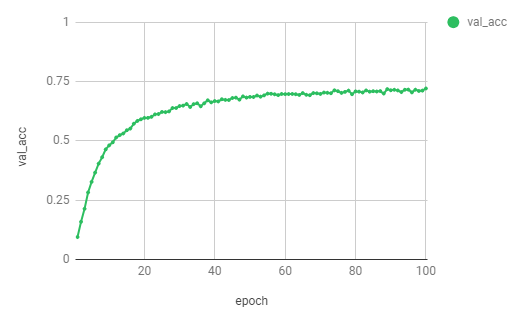
75%にも届かないような結果ですが,これである一応のモデルを完成させることができました!では,いよいよ作成したモデルで実際の食事画像を認識させてみましょう。
実際に画像を認識してみよう
ちょっと準備を...
では,実際に画像を認識していきましょう。その前に,例によって準備です。以下のコードを実行してください:
import requests
from keras.preprocessing import image
def download_img(url, file_name):
r = requests.get(url, stream=True)
if r.status_code == 200:
with open(file_name, 'wb') as f:
f.write(r.content)
def get_ctgname_by_index(index):
ary_ctgname = []
for line in open('./UECFOOD100/category_ja_utf8.txt', 'r'):
ary_ctgname.append(line[:-1].split())
ctg_dic = train_generator.class_indices
key = [k for k, v in ctg_dic.items() if v == index]
id = int(key[0])
ctg_name_index = 1
ctg_name = ary_ctgname[int(id)][ctg_name_index]
return ctg_name- 4-8行目:指定されたURLから画像をダウンロードしてくる関数を定義しています。
- 10-20行目:画像認識した結果から,それがどの食事に該当するのかを返す関数を定義しています。どのカテゴリがどの食事に該当するのかはUECFOOD100/category_ja_utf8.txtにありますので,そこから取得しています。
画像の認識・分類結果を表示しよう
では,画像をダウンロードし,それがどの食事に該当するのかを確認してみましょう。以下のコードを実行してください。
url = 'http://www.kikkoman.co.jp/homecook/search/recipe/img/00005991.jpg'
filename = 'sample.jpg'
download_img(url, filename)
img = image.load_img(filename, target_size=(224, 224))
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0)
x = x / 255.0
pred = model.predict(x)[0]
K = 5
unsorted_max_indices = np.argpartition(-pred, K)[:K]
y = pred[unsorted_max_indices]
indices = np.argsort(-y)
top5_indices = unsorted_max_indices[indices]
for index in top5_indices:
ctg_name = get_ctgname_by_index(index)
print(ctg_name + ":" + str(pred[index]))- 1-3行目:URLから画像を取得しています。先ほど定義した関数を使用しています。ちなみに,このURLの画像は以下の画像を拝借しています。
- 5-8行目:画像をピクセル配列に変換し,トレーニング画像などと同じように正規化しています。
- 10行目:予測しています。model.predictの引数に画像を指定しています。結果は画像枚数分の配列でかえってきますが,画像は1枚なので1つめだけを指定し取得しています。
- 12-16行目:値が上位5つのインデックスを取得しています。
- 18-20行目:その上位5つのインデックスを先で指定した関数で検索し,プリントしています。
上記では画像として,以下の白ごはんの画像を利用しています。

実行した結果,以下の結果が出力されました:
ごはん:0.99627364
炊き込みご飯:0.0026703866
ポテトサラダ:0.00052686787
コーンスープ:0.00023389162
カレーライス:0.00010246649白ごはんは結構特徴的な画像なので,しっかりと予測(約99%)できていますね!
では,次はうな重なんていかがでしょうか。

引用元のURLを先ほどのコードのURL部と置き換えて再度実行してみてください。今回は以下のような結果が得られました:
うな重:0.99999666
干物:1.3625669e-06
たたき:1.2055027e-06
角煮:5.5577556e-07
さんまの塩焼:6.616854e-08こちらもしっかりと予測できています。では少し難しそうなサンドイッチなんてどうでしょうか。以下の画像を認識してみましょう。

サンドウィッチ:0.9754837
さんまの塩焼:0.006933085
たたき:0.0052157417
刺身:0.0033492015
マカロニサラダ:0.0010272001こちらもしっかりと認識できてますね!こんな感じでしっかりと食事が写っているような画像だといい感じに認識できますね!
まとめ
今回はVGG16を食事画像認識用のFine-tuningし,実際に学習→判定までを行ってみました。
今巷で流行している食事画像認識AIの一端にふれることができて良かったなーと感じています。
実は画像をトリミングする必要があることを最初は知らず,トリミングせずに学習して,全く精度がでないという事態に陥っていました…。Twitter上でこのことを知らせてくれた@negi111111さんには感謝です。