みなさん,こんにちは。
シンノユウキ(shinno1993)です。
今回は自分のブログの文章の特徴をワードクラウドで可視化する方法を紹介したいと思います.今回はWordPressを対象としていますので,違うサービスを利用している方は少し工夫が必要になります.
では行きましょう!
ブログ記事をCSVでエクスポートしよう!
まずは,ブログ記事をエクスポートする必要があります.URLから直接読み込んでいく方法もあるにはあるのですが,面倒なので,CSVでブログの記事本文をエクスポートしちゃいましょう.
WordPressの場合はプラグイン:「WP CSV Exporter」を使用すると便利です.もちろん,記事の本文が取得できれば良いので,他のプラグインを使用しても構いません.
エクスポートする項目は記事本文を示している「Post Content」以外はお好みで構いません.
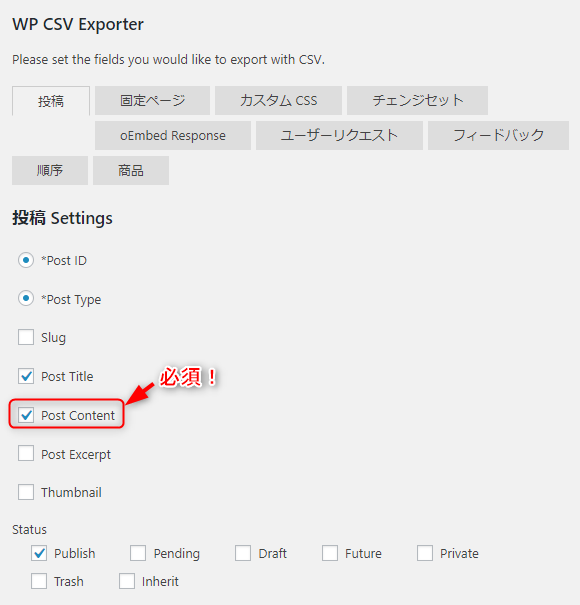
また,記事の期間を指定することもできます.今回は,2018年に公開した記事を対象にしました.
エクスポートすると以下のようなCSVファイルがダウンロードできるかと思います.
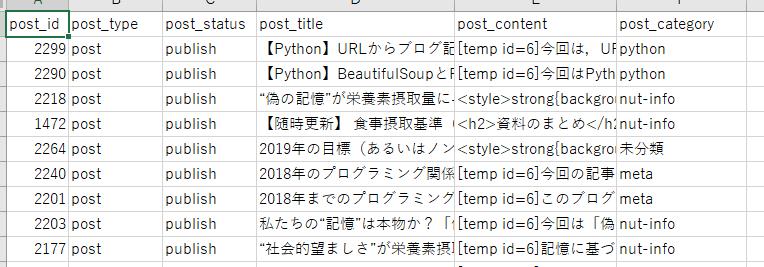
これをPythonで扱っていきます.
今回使用するライブラリたち
では,いよいよPythonの方での作業となります.以下のコードを記述し,今回使用するライブラリたちを読み込んで下さい:
import csv import html2text import re from janome.tokenizer import Tokenizer from wordcloud import WordCloud import matplotlib.pyplot as plt
- csv:CSVファイルを読み書きするための標準ライブラリです.
- html2text:HTMLファイルをプレーンテキストなどに変換するライブラリです.
- re:文字列の正規表現による置換などに使います.
- janome:形態素解析を行うためのライブラリです.
- WordCloud:ワードクラウドを描くためのライブラリです.
- matplotlib:グラフを書くためのライブラリです.
以下で使い方などは解説していきますので,とりあえず書いてしまいましょう.
CSVファイルを読み込もう!
では,次はCSVファイルを読み込んでいきます.以下のコードを実行してください:
file_path = "./*****.csv"
csv_file = open(file_path, "r", encoding="shift-jis", errors="", newline="")
f = csv.reader(csv_file, skipinitialspace=True)
header = next(f)
text = ""
for row in f:
text += " " + row[4]
file_pathには,先ほどエクスポートしたCSVファイルのパスを入れて下さい.CSVファイルを開き,変数fにCSVの中身のようなものを入れています.
その中身をfor row in f: で一行ずつ取り出しています.row[4]がブログの本文が格納されている場所ですので,それをtextにスペース区切りで結合していっています.
この処理が終わると,全ての記事の本文がtextに含まれている状態になります.
文章をクリーニングしよう!
エクスポートされた文章は,HTMLのタグが含まれていたり,URLなど重要でない単語が含まれているなど,そのままの状態でワードクラウドを作成できるような状態ではありません.なので,以下でその文章をクリーニングしていきます.
不要な文字の削除
HTMLのタグ
まずは,記事中に含まれる不要な文字の代表格,HTMLのタグを削除していきましょう.
これには,ライブラリ:html2textを使用します.以下のコードを実行してください:
h = html2text.HTML2Text() text = h.handle(text)
この状態でtextをprintしてみましょう.HTMLのタグが取り除かれた状態で出力されたかと思います.
URLの除外
その他,URLがtextに含まれる場合があるので,それを削除します.これには,reライブラリを使用します.以下のコードを実行してください:
text = re.sub("(https?|ttp)(:\/\/[-_\.!~*\'()a-zA-Z0-9;\/?:\@&=\+\$,%#]+)", " " ,text)
これは,正規表現を用いて,httpsもしくはhttpから始まる英数字の文字列を半角スペースに置き換えています.URLを除外する方法はいくつかあるのですが,この方法が最も簡単にできましたので,紹介しています.
これで,ある程度,不要な文字を削除することができました!
わかち書き
次は,textをワードクラウドで扱えるようにするために,わかち書きと呼ばれる書き方に変更します.これにはJanomeを使用します.このわかち書きにする方法については,以下の記事でも同様に使っていますので,併せて参照してみてください:

では,以下のコードを実行してください:
t = Tokenizer()
tokens = t.tokenize(text)
words = []
for token in tokens:
word = token.surface
part_of_speech = token.part_of_speech.split(',')[0]
part_of_speech2 = token.part_of_speech.split(',')[1]
if part_of_speech == "名詞":
if(part_of_speech2 != "非自立") and (part_of_speech2 != "代名詞"):
words.append(word)
word_list=" ".join(words)
janomeで形態素解析した単語をword_listにスペース区切りで結合しています.この際,ブログの特徴を示せるように,名詞で,かつ非自立でも代名詞でもない単語のみを抽出しています.
ここの処理は,ブログ記事の数や本文の量によって大きく変わります.多すぎると動かない?可能性もあるかもしれませんが,私程度であれば問題ありませんでした.
ワードクラウドを作成しよう!
では,最後にワードクラウドを作成しましょう.
以下のコードを実行してください:
wordcloud = WordCloud(
font_path='C:\Windows\Fonts\meiryo.ttc',
width=1200, height=630,
background_color="white",
).generate(word_list)
plt.figure(figsize=(100,50))
plt.imshow(wordcloud)
plt.axis("off")
plt.show()
これで,ワードクラウドを描くことができます.
私の場合,以下のようになりました:

うーん.分からないでもないですが,一般的に多用されている言葉が多い印象ですね.「場合」や「今回」など.なので,これらを除外して,より特徴を際立たせるようにしてみましょう.
データをクリーニングする際に,以下のようなコードを追加してくだい:
text = re.sub("今回", " ", text)
text = re.sub("場合", " ", text)
text = re.sub("まとめ", " ", text)
text = re.sub("処理", " ", text)
text = re.sub("使用", " ", text)
text = re.sub("紹介", " ", text)
text = re.sub("必要", " ", text)
text = re.sub("表示", " ", text)
text = re.sub("利用", " ", text)
text = re.sub("作成", " ", text)
text = re.sub("入力", " ", text)
指定した言葉を,textから除外しています.私の場合はこれらの言葉を除外しましたが,ワードクラウドを見て不要だと思うものを削除してみてください.
微調整の結果,以下のようなワードクラウドを作成することができました!

結構,私のブログを反映できてるのでは?と感じていますが,いかがでしょう?
まとめ
今回は自分のブログ記事をテキストマイニングし,ワードクラウドとして表示する方法を紹介しました.結構簡単で手軽にできますので,ぜひお試し下さい!