
みなさん,こんにちは。
シンノユウキ(shinno1993)です。
Python記事の2つ目。前回は、「Janome」を使用して、形態素解析を行う方法を簡単に紹介しました。

今回は、これを使って、ユーザーから与えられた文章から、食品名や食品の重量を抽出し、栄養計算を行うスクリプトを作成しましたので、そのスクリプトの紹介と解説を行いたいと思います。
どんなことができる?
今回紹介するスクリプトでは、
- 食べた食品
- 食品の重量
を答えるだけで、そのエネルギー(カロリー)を算出してくれます。
まずは、食べた食品を入力します。
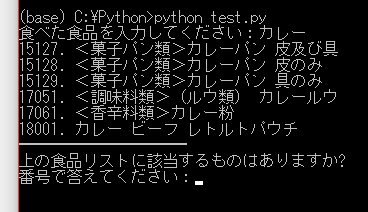
すると、以下の画面のように、食べた食品に該当すると思われる食品の一覧が表示されます。
この一覧で該当する食品の番号を入力します。
そして、その食品の重量をグラムで入力します。

その結果、その食品のエネルギーが算出されるという仕組みです。

スクリプト全文
では、スクリプトの全文を公開します。
import requests
from janome.tokenizer import Tokenizer
def search_food_from_web(word):
url = "https://script.google.com/macros/s/AKfycbzO6IMoPPbtBLb_AnRwgB1OheJyF5XwgNyj28NZdyjg76q4AzX0/exec"
name = {'name':word}
ret = requests.get(url, params=name).json()
foods = []
for key,value in ret.items():
food_num_name = value.split(',')
foods.append(food_num_name)
return foods
def calc_nut_from_web(food_num, weight):
url = "https://script.google.com/macros/s/AKfycbx7WZ-wdIBLqVnCxPwzedIdjhC3CMjhAcV0MufN2gJd-xsO3xw/exec"
param = {'num':food_num,'weight':weight}
ret = requests.get(url, params=param).json()
for key,value in ret.items():
return(ret)
def sum_list(ary):
ret = []
for foods in ary:
if foods: #foodsがnullの場合は追加しない。
for food in foods:
ret.append(food)
return ret
def search_food_from_list(food_num, foods_list):
for food in foods_list:
if food[0] == food_num:
return food
return None
def extract_noun(sentence):
tokens = t.tokenize(sentence)
words = []
for token in tokens:
part_of_speech = token.part_of_speech.split(',')[0]
if part_of_speech == u'名詞':
word = token.surface
words.append(word)
return words
def extract_number(sentence):
tokens = t.tokenize(sentence)
words = []
for token in tokens:
part_of_speech = token.part_of_speech.split(',')[1]
if part_of_speech == u'数':
number = token.surface
return int(number)
t = Tokenizer()
msg = input('食べた食品を入力してください:')
words = extract_noun(msg)
#名詞ごとに該当する食品を集める
word_foods = []
for word in words:
foods = search_food_from_web(word)
word_foods.append(foods)
#名詞ごとの食品を1つの配列に
foods_output = sum_list(word_foods)
for food in foods_output:
print(str(food[0]) + '. ' + food[1])
#番号で食品を答えてもらう
print('━━━━━━━━━━━━━━━━━━━━')
print('上の食品リストに該当するものはありますか?')
input_food_num = input('番号で答えてください:')
#入力された番号が正しいかを確認
food = search_food_from_list(input_food_num, foods_output)
if food is not None:
food_num = food[0]
food_name = food[1]
print('選択された食品は「' + food_name + '」です。')
sentence = input('食べた重量をグラムで入力してください:')
weight = extract_number(sentence)
nuts = calc_nut_from_web(int(food_num),weight)
energy = nuts['エネルギー(kcal)']
print('エネルギーは、' + str(energy) + '(kcal)です')
else:
print('入力された値が間違っています。')
print('始めからやり直してください。')
コードの解説
ではコードを解説していきます。
ライブラリのインポート
import requests from janome.tokenizer import Tokenizer
この二行で、今回使用するライブラリのインポートを行っています。今回のスクリプトでは、HTTPリクエストを行うのでライブラリ:requestsを、形態素解析を使用するのでライブラリ:Janomeをそれぞれインポートしています。
その次の行からは関数が並んでいますが、これは後ほど使用する際に紹介します。
食べた食品を抽出
t = Tokenizer()
msg = input('食べた食品を入力してください:')
words = extract_noun(msg)
最初の行でインスタンスを作成しています。
次の行でinputメソッドを使用し、食べた食品をユーザーに入力してもらいます。
そしてその食べた食品を、関数:extract_noun(msg)で名詞のみ抽出しています。関数の中身は以下の通りです。
def extract_noun(sentence):
tokens = t.tokenize(sentence)
words = []
for token in tokens:
part_of_speech =
if part_of_speech == u'名詞':
word = token.surface
words.append(word)
return words
文章を形態素解析し、品詞に該当する部分(token.part_of_speech.split(',')[0])が名詞の場合のみ、それをリスト:wordsに挿入しています。
文章を形態素解析し、名詞を抽出することで、少し曖昧な文章からでも食品を抽出できます。たとえば、「カレーを食べました」とか「食べたのはカレーです」といった文章を入力された際でも、名詞である「カレー」を抽出できます。
そして、抽出した名詞をリストとして、wordsに代入していあす。
名詞が食品かどうかを判定
次に、抽出した名詞が食品かどうかを判定します。これが次の部分です。
word_foods = []
for word in words:
foods = search_food_from_web(word)
word_foods.append(foods)
さきほど抽出した名詞が全てwordsに入っており、それを関数:search_food_from_web(word)にて食品かどうかを判定します。
この関数の中身は以下のようになっています。
def search_food_from_web(word):
url = "https://script.google.com/macros/s/AKfycbzO6IMoPPbtBLb_AnRwgB1OheJyF5XwgNyj28NZdyjg76q4AzX0/exec"
name = {'name':word}
ret = requests.get(url, params=name).json()
foods = []
for key,value in ret.items():
food_num_name = value.split(',')
foods.append(food_num_name)
return foods
ここで、HTTPリクエストを行っています。このURLは以前公開した、食品名から食品を検索するWeb APIのものです。

食品名をパラメータとして渡すことで、食品成分表から該当する食品の食品番号と食品名を引っ張ってくれます。そして、それをリスト:foodsに代入し、それを返しています。
そして、複数の名詞が存在してた場合に備えて、名詞ごとに検索した食品を1つのリストに結合します。それが以下のコードと関数です。もし、名詞として「私」などの非食品が抽出された場合、食品に該当するものはありませんので、foodsには値が含まれません。その場合はretに追加されないようになっています。
foods_output = sum_list(word_foods)
def sum_list(ary):
ret = []
for foods in ary:
if foods: #foodsがnullの場合は追加しない。
for food in foods:
ret.append(food)
return ret
食品一覧を表示
これで、リスト:foods_outputに抽出した食品の全てが含まれています。それを表示します。
for food in foods_output:
print(str(food[0]) + '. ' + food[1])
food[0]には食品番号が、food[1]には食品名が含まれています。なので、実際には以下のように表示されます。
15127. <菓子パン類>カレーパン 皮及び具
15128. <菓子パン類>カレーパン 皮のみ
15129. <菓子パン類>カレーパン 具のみ
17051. <調味料類>(ルウ類) カレールウ
17061. <香辛料類>カレー粉
18001. カレー ビーフ レトルトパウチ
そして、表示した食品の中で、どれが該当するかをユーザーに選択してもらいます。それが以下のコードです。
#番号で食品を答えてもらう
print('━━━━━━━━━━━━━━━━━━━━')
print('上の食品リストに該当するものはありますか?')
input_food_num = input('番号で答えてください:')
横線を出力しているのは、単純に見やすさのためです。
食品番号で入力してもらい、その値をinput_food_numに代入しています。
選択された食品を抽出
次のコードと関数で、選択された食品をfoods_outputから抽出しています。
food = search_food_from_list(input_food_num, foods_output)
def search_food_from_list(food_num, foods_list):
for food in foods_list:
if food[0] == food_num:
return food
return None
入力された食品が間違っている場合、Noneが返ってきますので、その場合はやりなおしとなります。
if food is not None:
#[中略]
else:
print('入力された値が間違っています。')
print('始めからやり直してください。')
重量からエネルギーを計算
if food is not None:
food_num = food[0]
food_name = food[1]
print('選択された食品は「' + food_name + '」です。')
sentence = input('食べた重量をグラムで入力してください:')
weight = extract_number(sentence)
nuts = calc_nut_from_web(int(food_num),weight)
energy = nuts['エネルギー(kcal)']
print('エネルギーは、' + str(energy) + '(kcal)です')
食品番号が正しく入力された場合は、いよいよ重量の入力です。ここでも、ユーザーから入力された値を形態素解析して、数字を抽出しています。関数:extract_number(sentence)です。
def extract_number(sentence):
tokens = t.tokenize(sentence)
words = []
for token in tokens:
part_of_speech = token.part_of_speech.split(',')[1]
if part_of_speech == u'数':
number = token.surface
return int(number)
コードは名詞の時と似ていますね。ただし、品詞ではなく、品詞細分類1を判定しています。token.part_of_speech.split(',')[1]となっています。これが’数’の場合に、それを抽出します。
なので、たとえば「食べたのは120グラムです」と入力された場合でも「120」の部分を抽出できます。
そして、エネルギーの計算にはWeb APIを使用しています。このAPIの詳細は以下からご覧ください。
関数は以下のようになっています。
def calc_nut_from_web(food_num, weight):
url = "https://script.google.com/macros/s/AKfycbx7WZ-wdIBLqVnCxPwzedIdjhC3CMjhAcV0MufN2gJd-xsO3xw/exec"
param = {'num':food_num,'weight':weight}
ret = requests.get(url, params=param).json()
for key,value in ret.items():
return(ret)
このエネルギーを表示したら完成です!
まとめ
今回は、形態素解析を用いて、対話形式で栄養計算できるスクリプトを作成しました。この程度だと、形態素解析を使う必要はないかもですが、将来的に複雑な処理をする場合にもっと活用できればと思っています。